Resilient Distributed Dataset – RDD
In this post we will understand the concept of Apache Spark RDD. RDD is the most basic building block in Apache Spark. RDD stands for Resilient Distributed Dataset.
- Resilient : Fault tolerant and is capable of rebuilding data on failure
- Distributed : Distributed data among the multiple nodes in a cluster
- Dataset : Collection of partitioned data with values
Let’s understand each of the above in detail below
Visit our post here to under the Apache Spark Architecture.
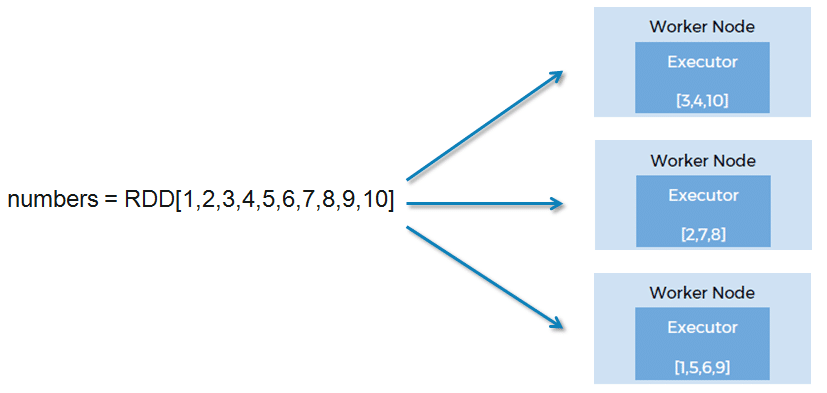
RDD as a distributed dataset
RDD is a collection of objects that is partitioned and distributed across nodes in a cluster. In the below figure we have an RDD numbers that contains ten elements. Now this RDD is not present on just one node. Spark partitions the RDD and distributes the data across multiple Worker nodes.
RDD is Resilient to failures
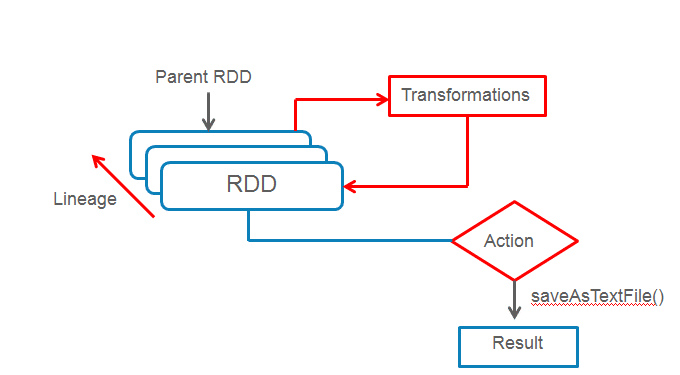
The second property of RDD is that it is able to recover from failures. Lets imagine that multiple tasks are running in the cluster and a node goes down. In such a scenario, Spark will re-compute the failed tasks on other worker nodes which are up and running. This happens with the help of DAG. When we write a Spark program, we are creating a directed acyclic graph which generates an RDD after every transform operation.
RDD is Immutable
Finally lets talk about the immutability of RDD. When a transformation is called on RDD, a new RDD is returned. None of the Spark operations modify an existing RDD. Instead, they create a new RDD. Immutable RDDs allow Spark to rebuild an RDD from the previous RDD in the pipeline if there is a failure.
By being immutable and resilient, RDD handles the failure of nodes in a distributed environment.
For example – We call transformations filter and map on an existing RDD orders. If the filteredOrders RDD fails for some reason, Spark will rebuilt it by applying the same filter operation on the previous RDD orders.
If RDDs were mutable, there is no guarantee that the orders RDD will be in the same form as it was at the first time when Spark called the filter operation on it.
RDD support Lazy Evaluation
RDDs support two types of operations – Transformations and Actions.
- Transformation operations create new RDD from an existing RDD without modifying them (because RDDs are immutable).
- Action operations are used at the end of a Spark pipeline to generate a result from the final RDD. A Spark program never executes until an action is encountered. This behavior is known as lazy execution.
By being lazy, RDDs avoid wasting the computing power for unwanted transformations.
Happy Learning 🙂
{kind=link}