Understanding Apache Spark Architecture
Apache Spark is an open-source cluster computing framework which is 100 times faster in memory and 10 times faster on disk when compared to Apache Hadoop. In this post , I will walk you through Spark Architecture and its fundamentals.
Apache Spark is an open source cluster computing framework for real-time data processing.
Spark Features
The main feature of Apache Spark is its in-memory cluster computing that increases the processing speed of an application. Spark provides an interface for programming entire clusters with implicit data parallelism and fault tolerance. It is designed to cover a variety of workloads such as batch applications, iterative algorithms, interactive queries, and streaming applications.
Speed
Spark runs up to 10-100 times faster than Hadoop MapReduce for large-scale data processing due to in-memory data sharing and computations.
Powerful Caching
Simple programming layer provides powerful caching and disk persistence capabilities.
Deployment
It can be deployed through Apache Mesos, Hadoop YARN and Spark’s Standalone cluster manager.
Real-Time
It offers Real-time computation & low latency because of in-memory computation.
Polyglot
Spark provides high-level APIs in Java, Scala, Python, and R. Spark code can be written in any of these four languages.
Spark Eco-System
Apache Spark ecosystem is composed of various components – Spark Core, Spark SQL, Spark Streaming, MLlib, GraphX and Spark R.
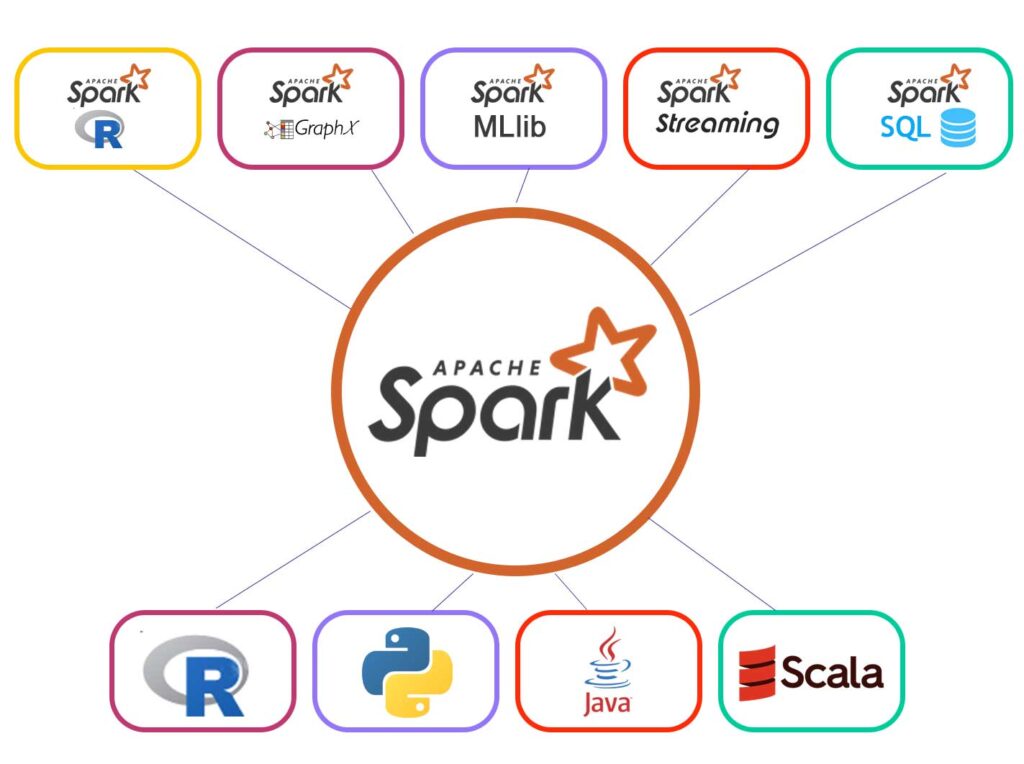
Lets talk about each component now –
Spark Core
Spark Core is the core engine for large-scale parallel and distributed data processing. Apart from being a processing engine, it also provides utilities and architecture to other components. It is responsible for memory management and fault recovery, scheduling, distributing and monitoring jobs on a cluster & interacting with storage systems.
Spark SQL
Spark SQL is a module for structured data processing in Spark which integrates relational processing with Spark’s functional programming API. It supports querying data either via SQL or via the Hive Query Language.
Spark Streaming
Spark Streaming component is a useful addition to the core Spark API. It is used to process real-time streaming data. It enables high-throughput and fault-tolerant stream processing of live data streams.
MLlib
MLlib stands is Machine Learning Library. Spark MLlib provides various machine learning algorithms such as classification, regression, clustering, and collaborative filtering. It also provides tools such as featurization, pipelines, persistence, and utilities for handling linear algebra operations, statistics and data handling.
GraphX
GraphX is the Spark API for graphs and graph-parallel computation. GraphX extends the Spark RDD abstraction by introducing the Resilient Distributed Property Graph, a directed multigraph with properties attached to each vertex and edge.
As you can see, Spark comes packed with high-level libraries, including support for R, SQL, Python, Scala, Java etc. These standard libraries increase the seamless integrations in a complex workflow. Over this, it also allows various sets of services to integrate with it like MLlib, GraphX, SQL + Data Frames, Streaming services etc. to increase its capabilities.
SparkR
SparkR is an R package that provides a light-weight front-end to use Apache Spark from R. In Spark 3.0. 0, SparkR provides a distributed data frame implementation that supports operations like selection, filtering, aggregation. SparkR also supports distributed machine learning using MLlib.
Spark Architecture Overview
Apache Spark has a well-defined layered architecture where all the spark components are loosely coupled. This architecture is further integrated with various extensions and libraries. Apache Spark Architecture is based on two main abstractions:
- Resilient Distributed Dataset (RDD)
- Directed Acyclic Graph (DAG)
Resilient Distributed Dataset ( RDD )
RDD is the most basic building block in Apache Spark.
- Resilient: Fault tolerant and is capable of rebuilding data on failure
- Distributed: Distributed data among the multiple nodes in a cluster
- Dataset: Collection of partitioned data with values
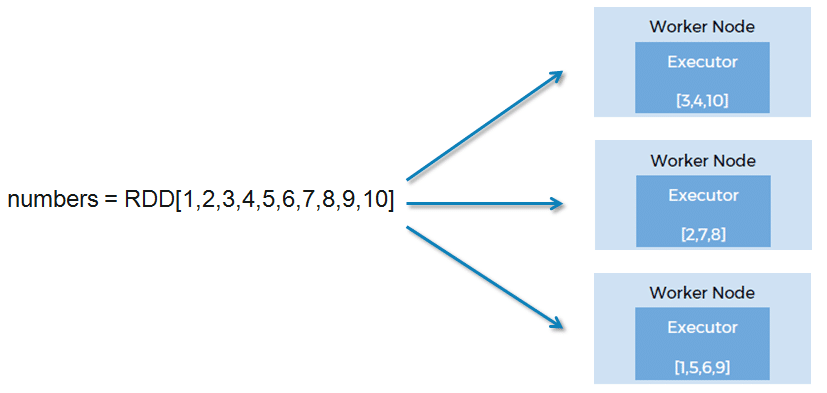
RDD as a distributed dataset
RDD is a collection of objects that is partitioned and distributed across nodes in a cluster. In the below figure we have an RDD numbers that contains ten elements. Now this RDD is not present on just one node. The RDD is partitioned and the data is distributed across multiple Worker nodes.
RDD is Resilient
RDD is resilient to failures. Multiple tasks are running in the cluster. Now if a node goes down while the tasks are running, the failed tasks can be recomputed on other worker nodes which are up and running. This happens with the help of DAG. When we write a Spark program, we are creating a directed acyclic graph which generates an RDD after every transform operations.
RDD is Immutable
RDDs are immutable. When a transformation is called on RDD, a new RDD is returned. None of the Spark operations modify an existing RDD. Instead, they create a new RDD. This behavior is known as immutability of RDD. Immutabe RDDs allow Spark to rebuild an RDD from the previous RDD in the pipeline if there is a failure.
By being immutable and resilient, RDD handles the failure of nodes in a distributed environment.
For example – We call transformations filter and map on an existing RDD “data”. If the filteredOrdersRDD fails for some reason, it can be rebuilt by applying the same filter operation on the previous RDD: orders. If RDDs are mutable there is no guarantee that the data RDD will be in the same form as it was at the first time Spark called the filter operation on it.
RDD support Lazy Evaluation
RDDs support two types of operations: Transformations and Actions. Transformation operations create new RDD from an existing RDD without modifying them (because RDDs are immutable).
Action operations are used at the end of a Spark pipeline to generate a result from the final RDD. A Spark program never executes until an action is encountered. This behavior is known as lazy execution.
By being lazy, RDDs avoid wasting the computing power for unwanted transformations.
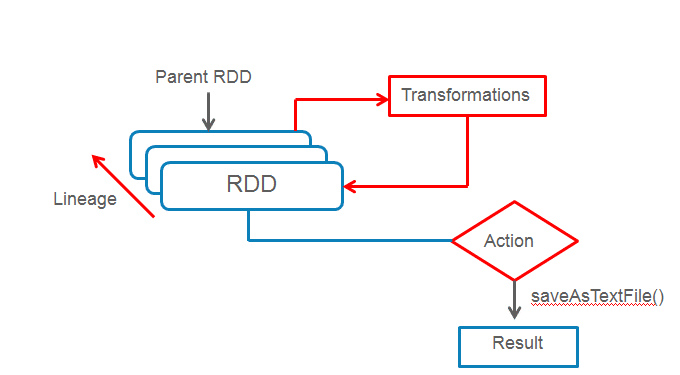
RDD Operations
- Transformations: They are the operations that are applied to create a new RDD.
- Actions: They are applied on an RDD to instruct Apache Spark to apply computation and pass the result back to the driver.
Working of Spark Architecture
As we have already seen the basic architectural overview of Apache Spark, now let’s dive deeper into its working.
In the master node, we have driver program, which drives the application. The code you are writing behaves as a driver program or if you are using the interactive shell, the shell acts as the driver program.

Driver program
- “Main” process coordinated by the SparkContext object
- Allows to configure any spark process with specific parameters
- Spark actions are executed in the Driver
- If we are using the interactive shell, the shell acts as the driver program.
SparkContext
- SparkContext is the main entry point for Spark functionality
- SparkContext represents the connection to a Spark cluster
- Tells Spark how & where to access a cluster
- Can be used to create RDDs, accumulators and broadcast variables on the cluster
Worker
- Any node that can run application code in the cluster
- Key Terms
- Executor: A process launched for an application on a worker node, that runs tasks and keeps data in memory or disk storage across them. Each application has its own executors.
- Task: Unit of work that will be sent to one executor
- Job: A parallel computation consisting of multiple tasks that gets spawned in response to a Spark action (e.g. save, collect)
Cluster Manager
- Cluster Manager is an external service for acquiring resources on the cluster
- Spark supports variety of cluster managers
- Local
- Spark Standalone
- Hadoop YARN
- Apache Mesos
- We have two deploy modes when the Cluster Manager is YARN
- Cluster – Framework launches the driver inside of the cluster
- Client – Driver runs in the client
Spark Execution Workflow
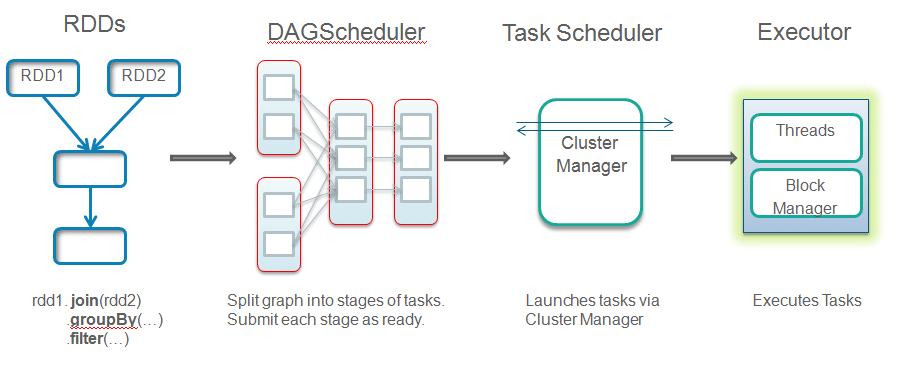
- When a job is submitted, driver implicitly converts user code that contains transformations and actions into a logically Directed Acyclic Graph called DAG. At this stage, it also performs optimizations such as pipelining transformations.
- DAG Scheduler converts the graph into stages. A new stage is created based on the shuffling boundaries.
- Now the driver talks to the cluster manager and negotiates the resources. Cluster manager launches executors in worker nodes on behalf of the driver. At this point, the driver will send the tasks to the executors based on data placement. When executors start, they register themselves with drivers. So, the driver will have a complete view of executors that are executing the task.
- While the job is running, driver program will monitor and coordinate the running tasks. Driver node also schedules future tasks based on data placement.
Spark example in Spark shell
Lets create and run a simple Spark word count program in Spark Shell. Sample data is shown below.
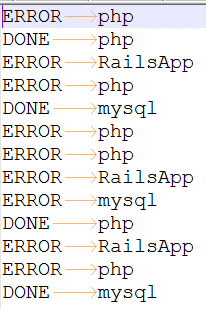
log.flatMap(line => line.split("\t"))
.map(ele => (ele,1))
.reduceByKey((x,y) => x +y)
.collect
.foreach(println)
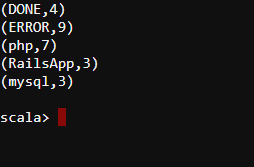
Output
{kind=link}