Different ways to create Spark RDD
In this post we will learn how to create Spark RDD in different ways. Visit our RDD tutorial to know more about Resilient distributed datasets.
- Spark RDD from local collection
- Creating an RDD from a text file or reading from database
- Creating from another RDD
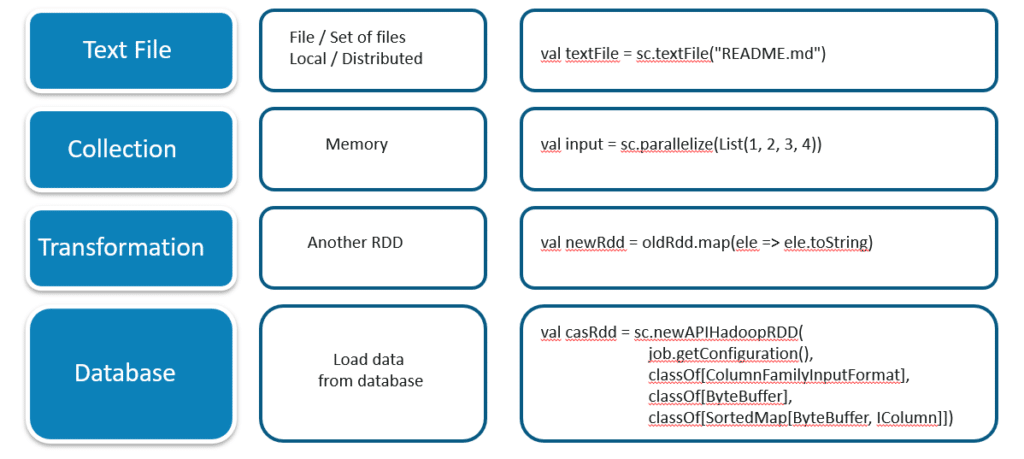
Creating RDD from local collection
Let’s look into the first way to create RDD. SparkContext provides parallelize method which accepts a Scala collection as an input argument and returns an RDD. We can use this method while doing prototyping or in testing some program logic. We can also set the number of partitions as second parameter to parallelize .
def parallelize[T](seq: Seq[T],numSlices: Int)(implicit evidence$1: scala.reflect.ClassTag[T]): org.apache.spark.rdd.RDD[T]
Here,
seq: Seq[T] : Local Scala collection.
numSlices: Int : Number of partitions.
Example
// Creating a local Scala collection.
scala> val days = List("Sunday","Monday","Tuesday","Wednesday","Thursday","Friday","Saturday")
days: List[String] = List(Sunday, Monday, Tuesday, Wednesday, Thursday, Friday, Saturday)
// Using sc (SparkContext) to create RDD.
scala> val daysRDD = sc.parallelize(days)
daysRDD: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[0] at parallelize at <console>:26
// Collect and show RDD contents.
scala> daysRDD.collect.foreach(println)
Sunday
Monday
Tuesday
Wednesday
Thursday
Friday
Saturday
Creating RDD from a text file
We can create an RDD by reading a text file , Hadoop dataset or by reading from a database like Cassandra, HBase etc. In this example we will read a text file using SparkContext’s textFile method.
You can download the dataset from our Github.com repository https://github.com/proedu-organisation/CCA-175-practice-tests-resource/tree/master/retail_db/categories
import org.apache.spark.sql.SparkSession
object RDDCreationFromTextFile extends App {
val file = "src/main/resources/retail_db/categories"
// Creating a SparkContext object.
val sparkContext = SparkSession.builder()
.master("local[*]")
.appName("Proedu.co examples")
.getOrCreate()
.sparkContext
// Set Log level to ERROR to suppress INFO level logs.
sparkContext.setLogLevel("ERROR")
// Reading a text file.
val dataRDD = sparkContext.textFile(file)
dataRDD.take(10).foreach(println)
}
Output
1,2,Football 2,2,Soccer 3,2,Baseball & Softball 4,2,Basketball 5,2,Lacrosse 6,2,Tennis & Racquet 7,2,Hockey 8,2,More Sports 9,3,Cardio Equipment 10,3,Strength Training
Now let’s read a directory of text files using the wholeTextFiles method. The files can be present in HDFS, a local file system , or any Hadoop-supported file system URI. In this scenario, Spark reads each file as a single record and returns it in a key-value pair, where the key is the path of each file, and the value is the content of each file. The encoding of the text files must be UTF-8.
For example : Our input path contains below files
src/main/resources/retail_db/categories-multipart part-m-00000 part-m-00001
Then val rdd = sparkContext.wholeTextFile(” src/main/resources/retail_db/categories-multipart “) will return the below RDD.
(/part-00000, its content) (/part-00001, its content)
Lets see the complete example now.
object WholeTextFilesExample extends App {
val file = "src/main/resources/retail_db/categories-multipart"
// Creating a SparkContext object.
val sparkContext = SparkSession.builder()
.master("local[*]")
.appName("Proedu.co examples")
.getOrCreate()
.sparkContext
// Set Log level to ERROR
sparkContext.setLogLevel("ERROR")
// Reading a text file.
val dataRDD = sparkContext.wholeTextFiles(file)
dataRDD.take(10).foreach(println)
}
Creating RDD from another RDD
Finally let’s see how to create an RDD from an existing RDD. Spark creates a new RDD whenever we call a transformation such as map, flatMap, filter on existing one.
For example : We have an RDD containing integer numbers as shown below
scala> val numRDD = sc.parallelize((1 to 100)) numRDD: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:24
When we apply a filter transformation on numRDD, a new RDD evenRDD is returned containing only even numbers.
// New RDD is returned by Spark. scala> val evenRDD = numRDD.filter(number => number % 2 == 0) evenRDD: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[1] at filter at <console>:25 // Output of new RDD scala> evenRDD.collect().foreach(println) 2 4 6 8 10 12 14 ...
Happy Learning 🙂
{kind=link}