In our previous posts we talked about mapPartitions / mapPartitionsWithIndex functions. In this post we will learn RDD’s reduceByKey transformation in Apache Spark.
As per Apache Spark documentation, reduceByKey(func) converts a dataset of (K, V) pairs, into a dataset of (K, V) pairs where the values for each key are aggregated using the given reduce function func, which must be of type (V,V) => V.
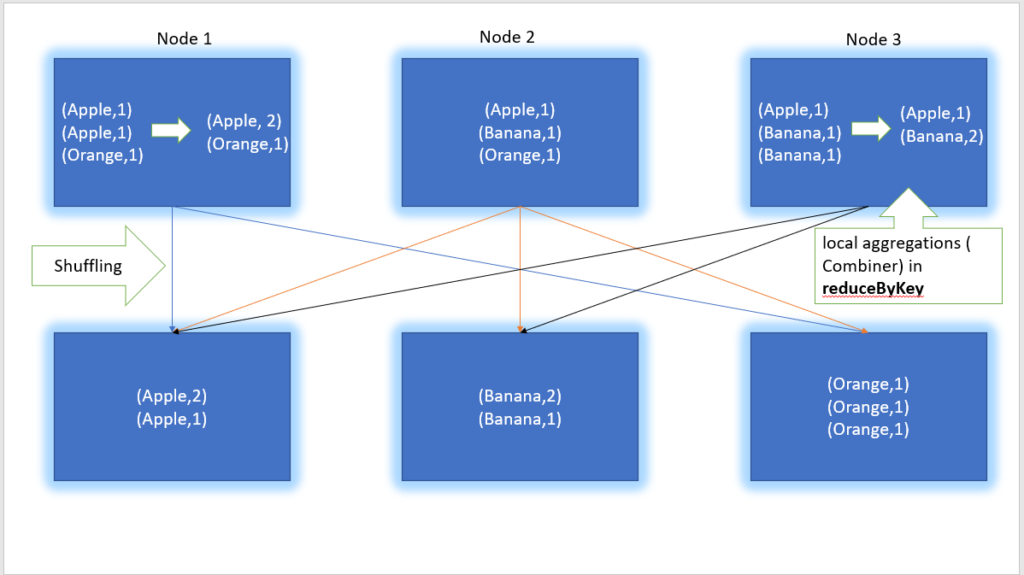
We have three variants of reduceBykey transformation
- The first variant reduceByKey(function) will generate hash-partitioned output with existing partitioner.
- The second variant reduceByKey(function, [numPartition]) will generate hash-partitioned output with number of partitions given by numPartition.
- The third variant reduceByKey(partitioner, function) will generate output using Partitioner object referenced by partitioner.
Let’s take an example. We will write a word count program using reduceByKey transformation. In the first step, we will read a server log file as shown below.
// File Location
val file = "src/main/resources/server_log"
// Creating a SparkContext object.
val sparkContext = SparkSession.builder()
.master("local[*]")
.appName("Proedu.co examples")
.getOrCreate()
.sparkContext
// Reading Server Log file as RDD.
val serverLogRDD = sparkContext.textFile(file)
// Let's print some data.
serverLogRDD.collect.foreach(println)
// Output
ERROR php
DONE php
ERROR RailsApp
ERROR php
DONE php
...
As a result, we have RDD of String. Now we will split each line by tab “\t” delimiter.
// Split each line by TAB delimiter.
val flattenedRDD = serverLogRDD.flatMap(line => line.split("\t"))
// Let's print some data.
flattenedRDD.collect.foreach(println)
// Output
ERROR
php
DONE
php
ERROR
RailsApp
After flattening the RDD as shown in the above step, we will convert each word into a tuple, for instance.
// Convert each word into a tuple. val tupleRDD = flattenedRDD.map(word => (word,1)) // Let's print some data. tupleRDD.collect.foreach(println) // Output (ERROR,1) (php,1) (DONE,1) (php,1) (ERROR,1) ...
Finally we will reduce the tuple using reduceByKey function as shown below
// Reducing the tuple to calculate the word count. val reducedRDD = tupleRDD.reduceByKey((x, y) => x + y) // Let's print some data. reducedRDD.collect.foreach(println) // Output (DONE,4) (ERROR,9) (php,7) (RailsApp,3) (mysql,3)
Complete example in Scala
The complete example is also present in out Github repository https://github.com/proedu-organisation/spark-scala-examples/blob/main/src/main/scala/rdd/transformations/ReduceByKeyExample.scala
import org.apache.spark.sql.SparkSession
object ReduceByKeyExample extends App {
val file = "src/main/resources/server_log"
// Creating a SparkContext object.
val sparkContext = SparkSession.builder()
.master("local[*]")
.appName("Proedu.co examples")
.getOrCreate()
.sparkContext
// Reading Server Log file as RDD.
val serverLogRDD = sparkContext.textFile(file)
// Let's print some data.
serverLogRDD.collect.foreach(println)
/** Output
* ERROR php
* DONE php
* ERROR RailsApp
* ERROR php
* DONE mysql
*/
// Split each line by TAB delimiter.
val flattenedRDD = serverLogRDD.flatMap(line => line.split("\t"))
// Let's print some data.
flattenedRDD.collect.foreach(println)
/** Output
* DONE
* mysql
* ERROR
* php
* ERROR
* php
* ERROR
*/
// Convert each word into a tuple.
val tupleRDD = flattenedRDD.map(word => (word, 1))
// Let's print some data.
tupleRDD.collect.foreach(println)
/** Output
* (ERROR,1)
* (php,1)
* (DONE,1)
* (php,1)
* (ERROR,1)
*/
// Reducing the tuple to calculate the word count.
val reducedRDD = tupleRDD.reduceByKey((x, y) => x + y)
// Let's print some data.
reducedRDD.collect.foreach(println)
/** Output
* (DONE,4)
* (ERROR,9)
* (php,7)
* (RailsApp,3)
* (mysql,3)
*/
}
Happy Learning 🙂
{kind=link}