Apache Spark RDD filter transformation
In our previous posts we talked about map and flatMap functions. In this post we will learn RDD’s filter transformation in Apache Spark.
As per Apache Spark documentation, filter(func) returns a new dataset formed by selecting those elements of the source on which func returns true.
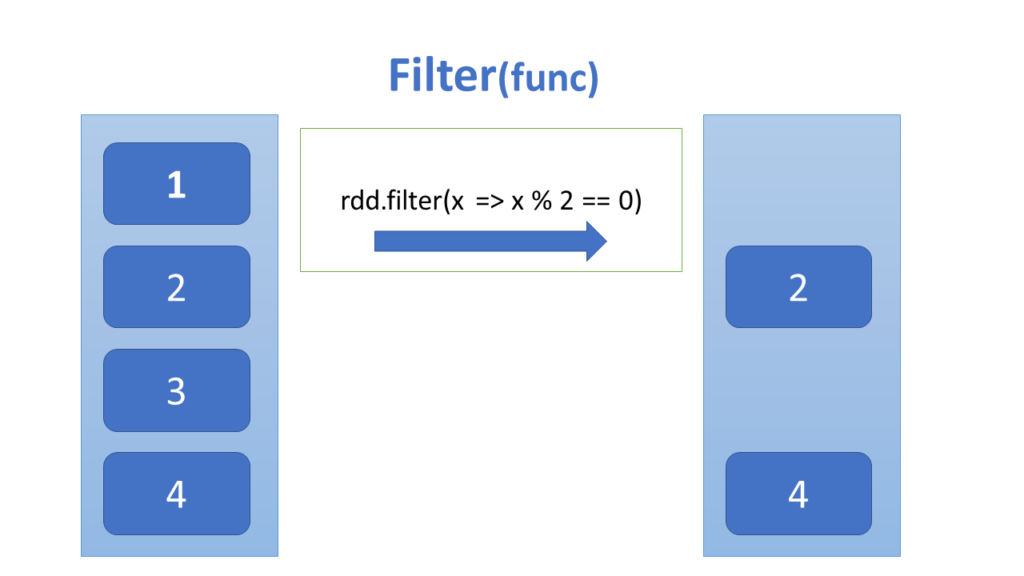
Lets take a very simple example. We have RDD of numbers and we want to filter only even numbers. We can achieve this using below code.
// RDD containing numbers. val numbersRDD = sc.parallelize(1 to 10) // Applying filter operation. val evenRDD = numbersRDD.filter(number => number % 2 == 0) // Printing the RDD evenRDD.collect.foreach(println) // Output 2 4 6 8 10
Complete Example
import org.apache.spark.sql.SparkSession
object FilterExample extends App {
// Creating a SparkContext object.
val sparkContext = SparkSession.builder()
.master("local[*]")
.appName("Proedu.co examples")
.getOrCreate()
.sparkContext
// RDD containing numbers.
val numbersRDD = sparkContext.parallelize(1 to 10)
// Applying filter operation.
val evenRDD = numbersRDD.filter(number => number % 2 == 0)
// Printing the RDD
evenRDD.collect.foreach(println)
}
Let’s take one more example. Here we will read orders dataset present in our Github repository. The data looks like below
1,2013-07-25 00:00:00.0,11599,CLOSED 2,2013-07-25 00:00:00.0,256,PENDING_PAYMENT 3,2013-07-25 00:00:00.0,12111,COMPLETE 4,2013-07-25 00:00:00.0,8827,CLOSED 5,2013-07-25 00:00:00.0,11318,COMPLETE
Let’s filter only completed orders , that is where order status is COMPLETE.
In the first step, we will read the dataset using SparkContext’s textFile method.
// Creating a SparkContext object.
val sparkContext = SparkSession.builder()
.master("local[*]")
.appName("Proedu.co examples")
.getOrCreate()
.sparkContext
// Reading the Orders file. File may be present in HDFF/Local file system.
val ordersRDD = sparkContext.textFile(file)
// Let's print some records.
ordersRDD.take(10).foreach(println)
// Output
1,2013-07-25 00:00:00.0,11599,CLOSED
2,2013-07-25 00:00:00.0,256,PENDING_PAYMENT
3,2013-07-25 00:00:00.0,12111,COMPLETE
4,2013-07-25 00:00:00.0,8827,CLOSED
5,2013-07-25 00:00:00.0,11318,COMPLETE
After reading the data as RDD, we will apply the filter function. In the above RDD, every element is a String value containing four fields separated by Comma. To identify the completed records we can simply use contains function as shown below.
// Applying Filter operation to filter only COMPLETE orders. val completedOrders = ordersRDD.filter(record => record.contains("COMPLETE")) // Let's print some records. completedOrders.collect.foreach(println) // Output 68760,2013-11-30 00:00:00.0,3603,COMPLETE 68761,2013-12-04 00:00:00.0,6402,COMPLETE 68764,2013-12-08 00:00:00.0,1735,COMPLETE 68768,2013-12-12 00:00:00.0,4150,COMPLETE 68772,2013-12-21 00:00:00.0,6054,COMPLETE
Complete Code
The complete example is also present in our Github repository https://github.com/proedu-organisation/spark-scala-examples/blob/main/src/main/scala/rdd/transformations/FilterExample2.scala
Happy Learning 🙂
{kind=link}